Robots.txt Generator
The Free Robots.txt Generator allows you to easily product a robots.txt files help ensure Google and other search engines are crawling and indexing your site properly.
If you use this great tool then please comment and/or like this page.
Average Rating: Tool Views: 319
Average Rating: Tool Views: 319
Subscribe for Latest Tools
How to use this Robots.txt Generator Tool?
How to use Yttags's Robots.txt Generator?
- Step 1: Select the Tool

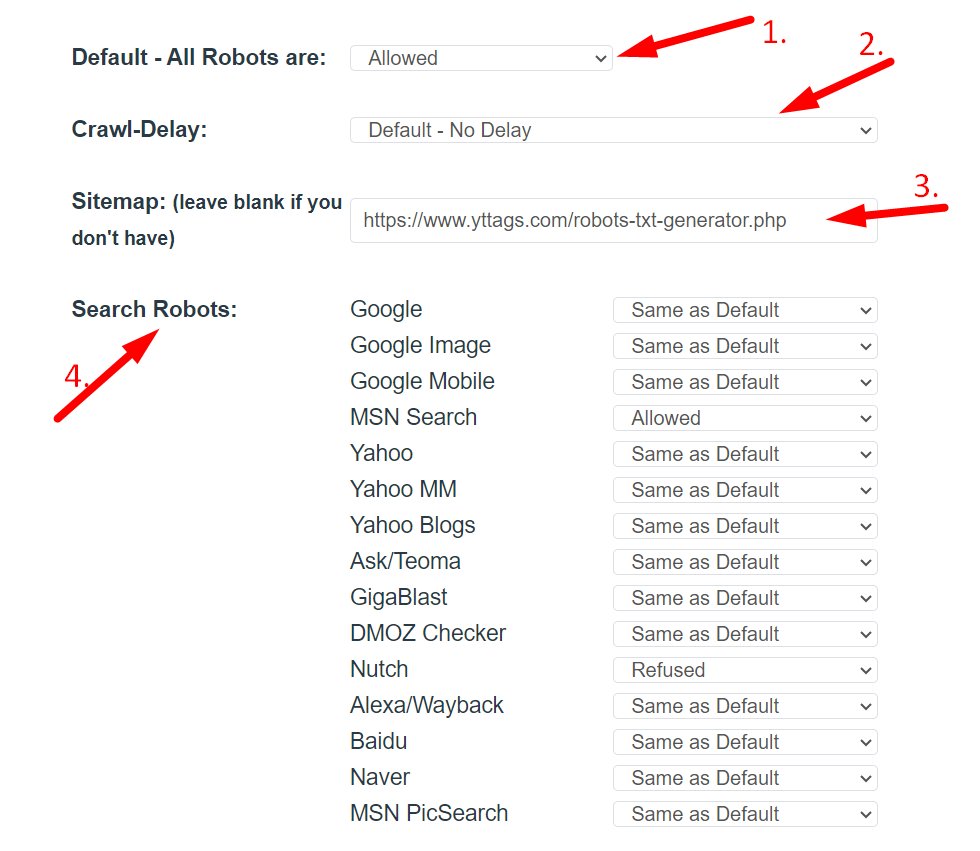
- Step 2: Select The Options
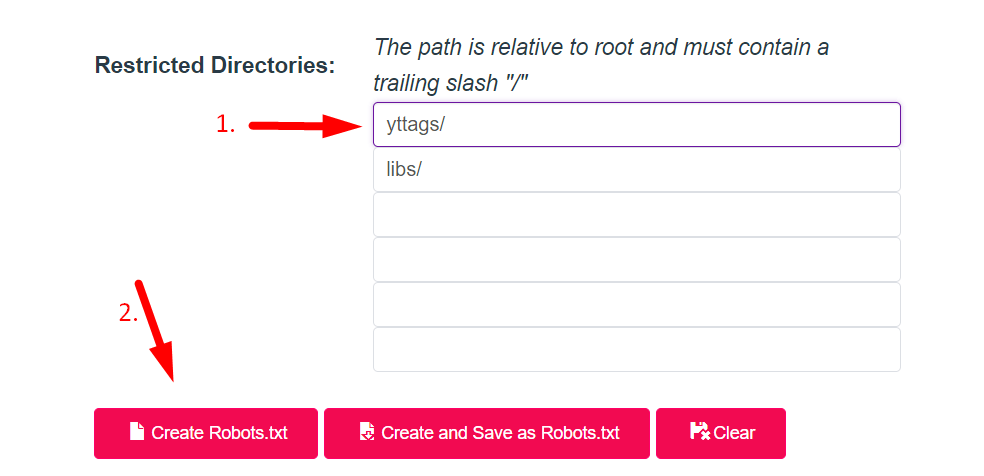
- Step 3: Enter Restricted Directories And Click On Create Robots.txt Button
- Step 4: Check Your Robots.txt Generator Result
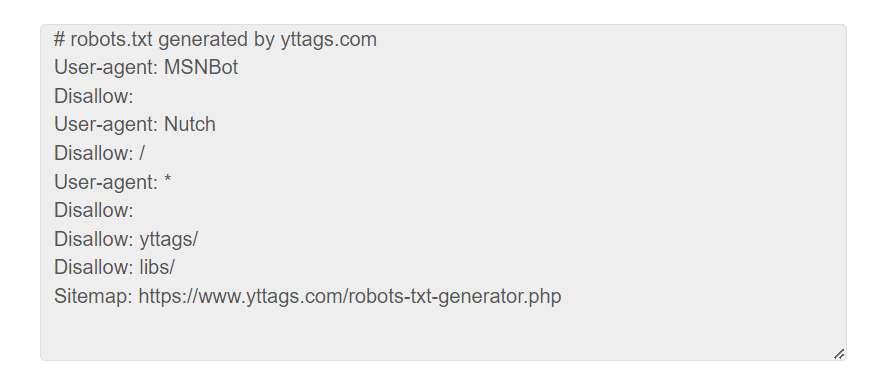
Online Robots.txt Generator Example
Below is an example of the original Robots.txt Generator and the result.
An example of how the online Robots.txt Generator works.
Robots.txt Generator Result# robots.txt generated by yttags.com User-agent: Googlebot Disallow: User-agent: Slurp Disallow: User-agent: * Disallow: Disallow: /cgi-bin/ Sitemap: https://www.yttags.com/sitemap.xml
If you want to link to Robots Txt Generator page, please use the codes provided below!

FAQs for Robots.txt Generator
What Is Robot Txt in SEO?
In SEO, the "robots.txt" file is a text file placed on a website's server to instruct search engine crawlers which pages or sections of the site should not be indexed or crawled.
How to write and submit a robots.txt file?
To write a robots.txt file, use a plain text editor and define the rules for search engine crawlers. Once created, upload the file to the root directory of your website's server to make it accessible to search engines. There is no need to submit the file; search engine crawlers automatically look for and follow the instructions in the robots.txt file.
How to read a robots.txt file?
To read a robots.txt file, simply enter the website's domain name followed by "/robots.txt" in the web browser's address bar. The file will be displayed in plain text format, showing the rules and directives for search engine crawlers.
How to use the Disallow directive properly?
To use the Disallow directive properly in a robots.txt file, specify the URLs or directories you want to prevent search engines from crawling by listing them after the "Disallow:" keyword. For example, "Disallow: /private" will block crawlers from accessing the "/private" directory.
How to use the Allow directive properly?
To use the Allow directive properly in a robots.txt file, specify the URLs or directories you want to allow search engines to crawl even if there is a broader Disallow rule. For example, "Allow: /public" would override a previous "Disallow: /" rule and allow crawling of the "/public" directory.
How to submit a robots.txt file to search engines?
You don't need to submit a robots.txt file to search engines. They automatically look for and follow the rules in the robots.txt file when crawling a website. Simply place the file in the root directory of your website's server to make it accessible to search engine crawlers.